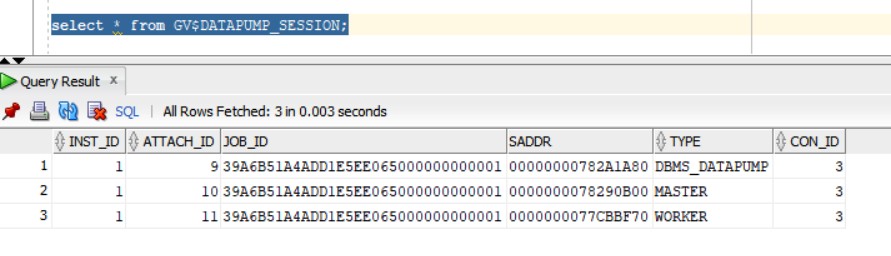
New and nice feature introduced in 23ai is the ability to view the progress of datapump operations through database views:
GV$DATAPUMP_PROCESS_INFO
GV$DATAPUMP_PROCESSWAIT_INFO
GV$DATAPUMP_SESSIONWAIT_INFO
GV$DATAPUMP_JOB
To simulate:
I will create a dummy account called “tim” and will grant the account “DBA” role.
SQL> alter session set container=FREEPDB1;
Session altered.
SQL> create user tim identified by tim123;
User created.
SQL> grant DBA to tim;
Grant succeeded.
SQL> alter user tim default role all;
User altered.
And I will define a directory :
SQL> create directory tmp as ‘/tmp’;
I will then execute the following export datapump command for simualtion (will take full pluggable database export backup):
expdp tim/tim123@//localhost:1521/FREEPDB1 directory=tmp FULL=Y dumpfile=test_dump.dmp logfile=EXP_TEST.log
The following view will show the account used for the export and operating system process id’s (SPID):

Wait event as shown below is “db file sequential read” for the datapump job: